Chain of Thought in RAG: Making Queries Smarter, Not Harder
I'm a dedicated and curious engineer with a strong passion for building technology that makes a difference. My journey in tech began with a deep interest in web development, which has grown into hands-on experience in full-stack development using modern frameworks and best practices. In addition to web development, I actively explore the fields of Web3 and cybersecurity. I enjoy learning about blockchain technologies, smart contracts, and decentralized applications—constantly seeking new ways to apply them in real-world scenarios. I believe in continuous learning, clean code, and solving real problems with thoughtful design and secure solutions.
When building RAG systems, one common problem shows up quickly:
The user asks one big question... but the system struggles to retrieve the right context. Because most user queries are too abstract.
So what are the steps involved in building a scalable and reliable distributed system?
The system would perform much better if that query were broken into smaller, focused questions.
That's exactly where Chain of Thought (CoT) comes in.
What is Chain of Thought (CoT)?
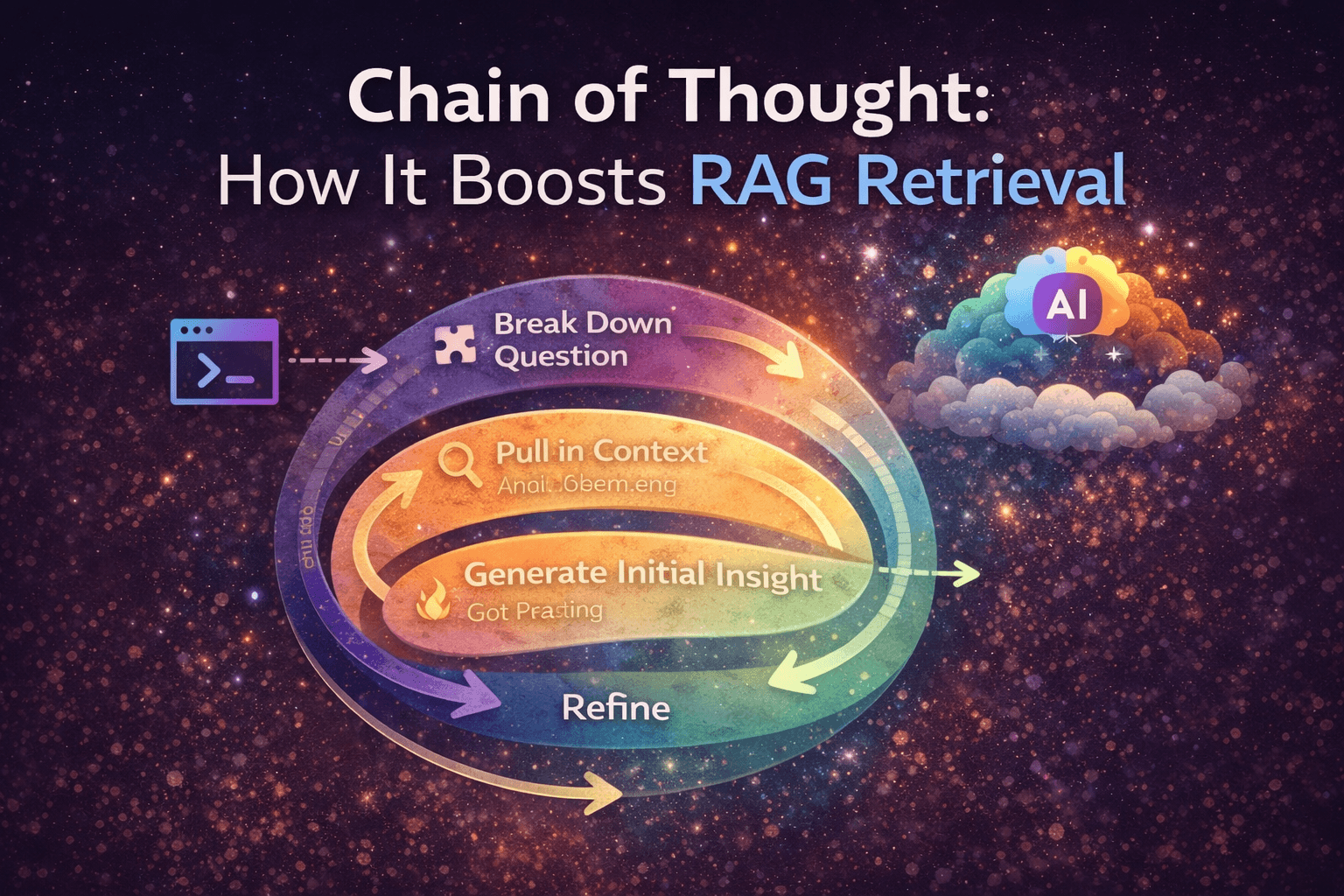
Chain of Thought is a technique where a complex query is broken into smaller, logical steps, and each step is processed one after another.
Instead of solving everything in one go, the system:
breaks the query
solves each part
uses previous results as context
gradually builds a better answer
Instead of jumping to the final answer instantly, reason step by step.
What CoT Matters in RAG Systems?
A typical RAG pipeline has three main steps:
Indexing → storing data as embeddings
Retrieval → fetching relevant information
Generation → producing the final answer
Usually, generation is not the problem; It's in retrieval
Let's say if the query is vague or broad, the retrieval step returns:
weak context
irrelevant chunks
incomplete information
And the final answer suffers.
This is the place where Chain of Thought helps.
What CoT Matters in RAG Systems?
CoT is applied in the retrieval stage.
Instead of sending one large query to the vector database, we:
Break the query into sub-queries
Process them sequentially
Use previous outputs to improve the next retrieval
So instead of:

We do:

How Chain of Thought Works (Step by Step)
Step 1: Break the query
Example: User Query → How does a scalable RAG system handle large traffic and ensure accurate responses?
LLM break into:
What is scalability in RAG systems?
How does retrieval work in RAG?
How do we improve retrieval accuracy?
Step 2: Process First Sub-query
Take the first sub-query
generate embeddings
perform a semantic search
retrieve relevant chunks
generate a response
Step 3: Pass Context Forward
The output of step 1 becomes the context for step 2. So instead of starting fresh every time, the system builds knowledge step by step.
Step 4: Repeat Sequentially
Continue this process:
Each sub-query uses previous responses
Context becomes richer
Retrieval becomes more precise
Step 5: Final Output
The response generated from the last sub-query becomes the final answer.
Example With Code
import os
import json
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("GROQ_API_KEY"),
base_url="https://api.groq.com/openai/v1"
)
system_prompt = """
You are an AI assistant who is expert in breaking down complex problems and then resolve the user query.
For the given user input, analyse the input and break down the problem step by step.
Atleast thing 5-6 steps on how to solve the problem before solving it down.
The steps are you get a user input, you analyse,you think, you again think for several times and then return an output with explanation and then finally you validate the output as well before giving final result.
Follow the steps in sequence that is "analyse", "think", "output", "validate" and finally "result".
Rules:
1. Follow the strict JSON output as per Output schema.
2. Always perform one step at a time and wait for next input
3. Carefully analyse the user query
Output Format:
{{ step: "string", content: "string" }}
Example:
Input: What is 2 + 2.
Output: {{ step: "analyse", content: "Alright! The user is interested in maths query and he is asking a basic arithmetic operation"}}
Output: {{ step: "think", content: "To perform the addition i must go from left t right and add all the operands.}}
Output: {{ step: "output", content: "4" }}
Output: {{ step: "validate", content: "seems like 4 is correct ans for 2 + 2" }}
Output: {{ step: "result", content: "2 + 2 = 4 and that is calculated by adding all numbers" }}
"""
messages = [
{"role": "system", "content": system_prompt},
]
query = input("> ")
messages.append({"role": "user", "content": query})
while True:
resonse = client.chat.completions.create(
model="llama-3.1-8b-instant",
response_format={"type": "json_object"},
messages=messages
)
parsed_response = json.loads(resonse.choices[0].message.content)
messages.append({"role": "assistant", "content": json.dumps(parsed_response)})
if parsed_response.get("step") != "output":
print(f"{parsed_response.get('step')}: {parsed_response.get('content')}")
continue
print(f"output: {parsed_response.get('content')}")
break
> what is 2 + 10 * 5
analyse: Alright! The user is interested in maths query and has a query with a mix of addition and multiplication operation with a BODMAS(Brackets,Order, Division, Multiplication, Addition, Subtraction) application required, where the first non bracketed operator is multiplication.
think: To solve this, I need to follow the BODMAS rule and perform operations from left to right. First, I will perform the multiplication and then add the result to 2. I need to consider 10 being multiplied by 5 to get the correct intermediate result before moving to next operation which is addition with 2.
think: First, I must consider multiplication. 10 * 5 = 50, which is the result of the first operation in the given expression. Now, I proceed to the addition of result 50 and 2.
output: 52
Why This Improves Accuracy
It reduces abstraction. Instead of asking one vague question, it focuses on smaller parts, retrieves focused information, and builds a layered context, which leads to better semantic search, more relevant chunks, and higher-quality responses.
When Should You Use CoT in RAG?
Chain of Thought is useful when queries are complex, questions involve multiple steps, context needs to be built gradually, and retrieval quality is poor.
Final Thoughts
RAG systems don't fail because generation is weak. They fail because retrieval is shallow.
Chain of Thought fixes this by:
breaking queries into meaningful steps
increasing context depth
improving semantic retrieval
If you found this useful, I write simple blogs on:
GenAI Systems, backend engineering, system design
Follow along to catch more.