Difference between Sharding and Partitioning
I'm a dedicated and curious engineer with a strong passion for building technology that makes a difference. My journey in tech began with a deep interest in web development, which has grown into hands-on experience in full-stack development using modern frameworks and best practices. In addition to web development, I actively explore the fields of Web3 and cybersecurity. I enjoy learning about blockchain technologies, smart contracts, and decentralized applications—constantly seeking new ways to apply them in real-world scenarios. I believe in continuous learning, clean code, and solving real problems with thoughtful design and secure solutions.
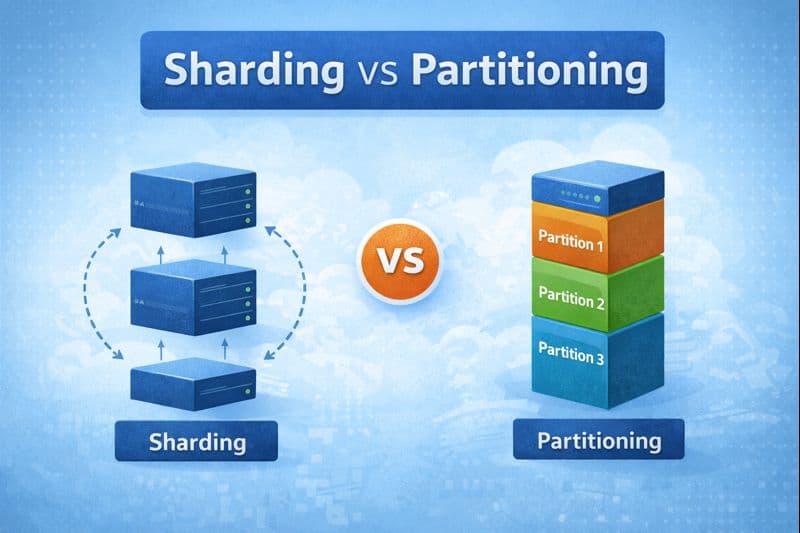
Sharding vs Partitioning: What’s the Real Difference?
As applications grow, databases often become the first bottleneck. Queries slow down, writes queue up, and suddenly the system that worked fine yesterday starts struggling today.
Two common techniques used to scale databases are Partitioning and Sharding.
They sound similar, are often used together, and are frequently confused — but they solve slightly different problems.
Let’s break them down in a simple, practical way.
Why Do Databases Need to Scale?
A database usually starts its life on a single machine. That machine has limited CPU, memory, disk, and network capacity.
As usage increases, the database experiences:
More write traffic
More read traffic
More stored data
At first, we try vertical scaling — upgrading the machine. But hardware has limits. When one machine can no longer handle the load, we need a different approach.
That’s where horizontal scaling enters the picture.
Horizontal Scaling in Databases
Horizontal scaling means distributing data across multiple database servers so that no single machine becomes a bottleneck.
Instead of one database handling everything, multiple databases share the load.
This is the foundation on which both partitioning and sharding are built.
What Is Partitioning?
Partitioning is about splitting data into smaller logical pieces.
All partitions may still live on:
The same database server, or
Different servers
But conceptually, the data is divided.
Example: Table Partitioning
Imagine a users table with millions of rows. Instead of storing everything together, the database can split it like:
Users with IDs 1–1M
Users with IDs 1M–2M
Users with IDs 2M–3M
Each chunk is a partition.
The database knows where each partition lives and routes queries accordingly.
Key Points About Partitioning
It is mainly a data organization technique
Often managed by the database engine
Improves query performance and manageability
Does not always imply multiple machines
What Is Sharding?
Sharding is about distributing data across multiple database servers.
Each server stores only a subset of the total data and handles queries for that subset.
That server is called a shard.
Example: User-Based Sharding
Suppose you have:
Shard A → users with IDs ending in 0–4
Shard B → users with IDs ending in 5–9
Each shard:
Stores different data
Handles its own reads and writes
Scales independently
Key Points About Sharding
Sharding is an architectural decision
Each shard is usually a separate database instance
Enables true horizontal scaling
Requires routing logic in the application or middleware
How Sharding and Partitioning Work Together
How Sharding and Partitioning Work Together
A common real-world setup:
The database is sharded across machines
Each shard internally uses partitions to manage its data
For example:
3 shards (3 database servers)
Each shard has 4 partitions
So the system has:
3 shards
12 partitions total
Advantages of Sharding
Sharding unlocks capabilities that a single database cannot provide:
Handles very high read and write traffic
Increases total storage capacity
Improves fault isolation
Enables independent scaling per shard
Challenges of Sharding
Sharding comes with trade-offs:
Operational complexity increases
Cross-shard queries are expensive
Transactions across shards are harder
Rebalancing shards is non-trivial
This is why sharding is usually adopted only when necessary.
When Should You Use What?
When to use Partitioning
Tables are large
Queries need optimization
You want better data organization
When to use Sharding
One database cannot handle the load
You need horizontal scalability
The system has reached hardware limits
Final Thoughts
Partitioning helps databases stay efficient.
Sharding helps systems grow beyond a single machine.
Most scalable systems use both, but only after carefully understanding the trade-offs.